|
I am a Ph.D. student at the Department of Computer Science, The University of Hong Kong (HKU), advised by Prof. Ping Luo. Before that, I obtained my master degree from University of Science and Technology of China (USTC), advised by Prof. Yang Cao. My previous research primarily centered around generative models, focusing on image, video, and 3D generation. Currently, my interests have shifted towards native multimodal models and long-context modeling. I am always open to research discussions and collaborations; please feel free to contact me via email (zhihengl0528@connect.hku.hk). I am also happy to discuss any new graduate or internship opportunities. |

|
News
|
Selected Publications |
|
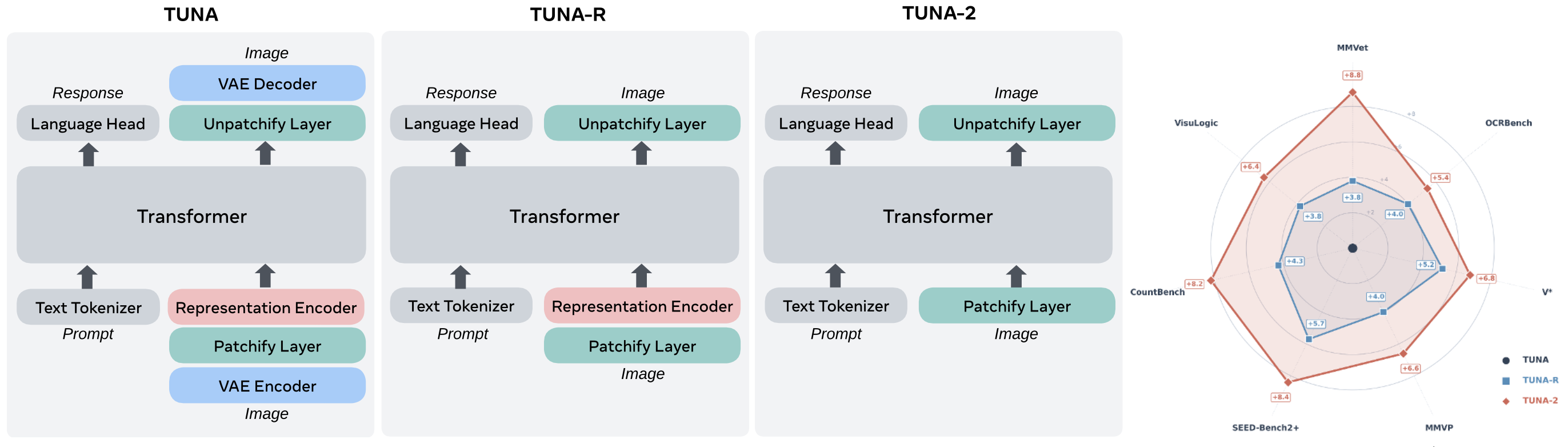
Tuna‑2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation Zhiheng Liu*, Weiming Ren*, Xiaoke Huang, Shoufa Chen, Tianhong Li, Mengzhao Chen, Yatai Ji, Sen He, Jonas Schult, Belinda Zeng, Tao Xiang, Wenhu Chen, Ping Luo, Luke Zettlemoyer, Yuren Cong arXiv preprint, 2026 pdf / page Evolution of the Tuna‑2 architecture and multimodal performance comparison. We simplify Tuna by progressively stripping away its visual encoding components. By removing the VAE, we first derive Tuna‑R, a pixel-space UMM that relies solely on a representation encoder. Tuna‑2 further streamlines the design by bypassing the representation encoder entirely, utilizing direct patch embedding layers for raw image inputs. Tuna‑2 using pixel embeddings outperforms both Tuna‑R and Tuna across a diverse suite of multimodal benchmarks. |

|
TUNA: Taming Unified Visual Representations for Native Unified Multimodal Models Zhiheng Liu*, Weiming Ren*, Haozhe Liu, Zijian Zhou, Shoufa Chen, Haonan Qiu, Xiaoke Huang, Zhaochong An, Fanny Yang, Aditya Patel, Viktar Atliha, Tony Ng, Xiao Han, Chuyan Zhu, Chenyang Zhang, Ding Liu, Juan‑Manuel Perez‑Rua, Sen He, Jürgen Schmidhuber, Wenhu Chen, Ping Luo, Wei Liu, Tao Xiang, Jonas Schult, Yuren Cong CVPR, 2026 Highlight pdf / page Introduces Tuna, a native Unified Multimodal Model (UMM) for continuous visual representation in end-to-end image & video processing. |

|
WorldWeaver: Generating Long-Horizon Video Worlds via Rich Perception Zhiheng Liu, Xueqing Deng, Shoufa Chen, …, Linjie Yang NeurIPS, 2025 pdf / page Framework for long-horizon video generation unifying RGB & perceptual conditions, leveraging depth-guided memory & segmented noise scheduling. |

|
DepthLab: From Partial to Complete Zhiheng Liu*, Ka Leong Cheng*, Qiuyu Wang, …, Ping Luo arXiv, 2024 pdf / page Robust depth inpainting foundation model for downstream tasks to enhance performance. |

|
InFusion: Inpainting 3D Gaussians via Learning Depth Completion from Diffusion Prior Zhiheng Liu*, Hao Ouyang*, Qiuyu Wang, …, Yang Cao CVPRW HiGen, 2026 Oral pdf / page Image-conditioned depth inpainting model using diffusion prior for 3D Gaussians, ensuring geometric & texture consistency. |

|
MangaNinja: Line Art Colorization with Precise Reference Following Zhiheng Liu*, Ka Leong Cheng*, Xi Chen, …, Ping Luo CVPR, 2025 Highlight pdf / page Reference-based line art colorization method for precise matching & fine-grained interactive control. |

|
LivePhoto: Real Image Animation with Text-guided Motion Control Xi Chen, Zhiheng Liu, Mengting Chen, …, Hengshuang Zhao ECCV, 2024 pdf / page Real image animation method with text guidance; preserves object identity accurately. |

|
Cones 2: Customizable Image Synthesis with Multiple Subjects Zhiheng Liu*, Yifei Zhang*, Yujun Shen, …, Yang Cao NeurIPS, 2023 pdf / page Flexible subject composition with minimal storage per subject (~5 KB), no model tuning required. |
|
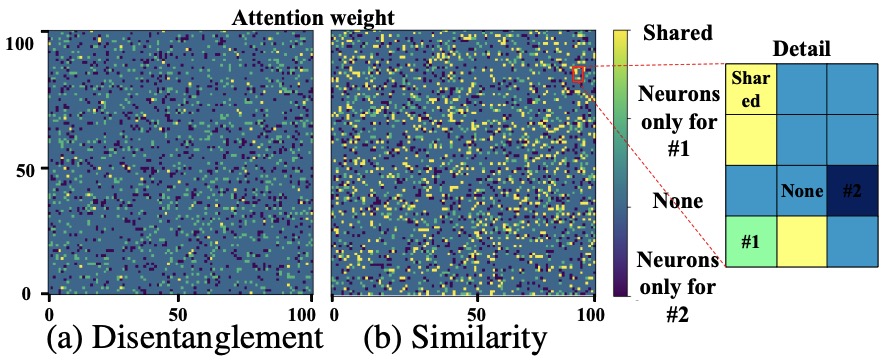
Cones: Concept Neurons in Diffusion Models for Customized Generation Zhiheng Liu*, Ruili Feng*, Kai Zhu, …, Yang Cao ICML, 2023 Oral pdf / page Explores subject-specific concept neurons in a text-to-image diffusion model for flexible multi-concept generation. |
| Design and source code from Jon Barron's website |